
Organization of Datasets
Choosing one well-conceived system of data organization can help keeping on track with your data if there are multiple versions of data sets or changes in data sets. This holds especially in larger teams. To begin with your data organization, you have to define the structure of your research data. Most important structure types are shown below:
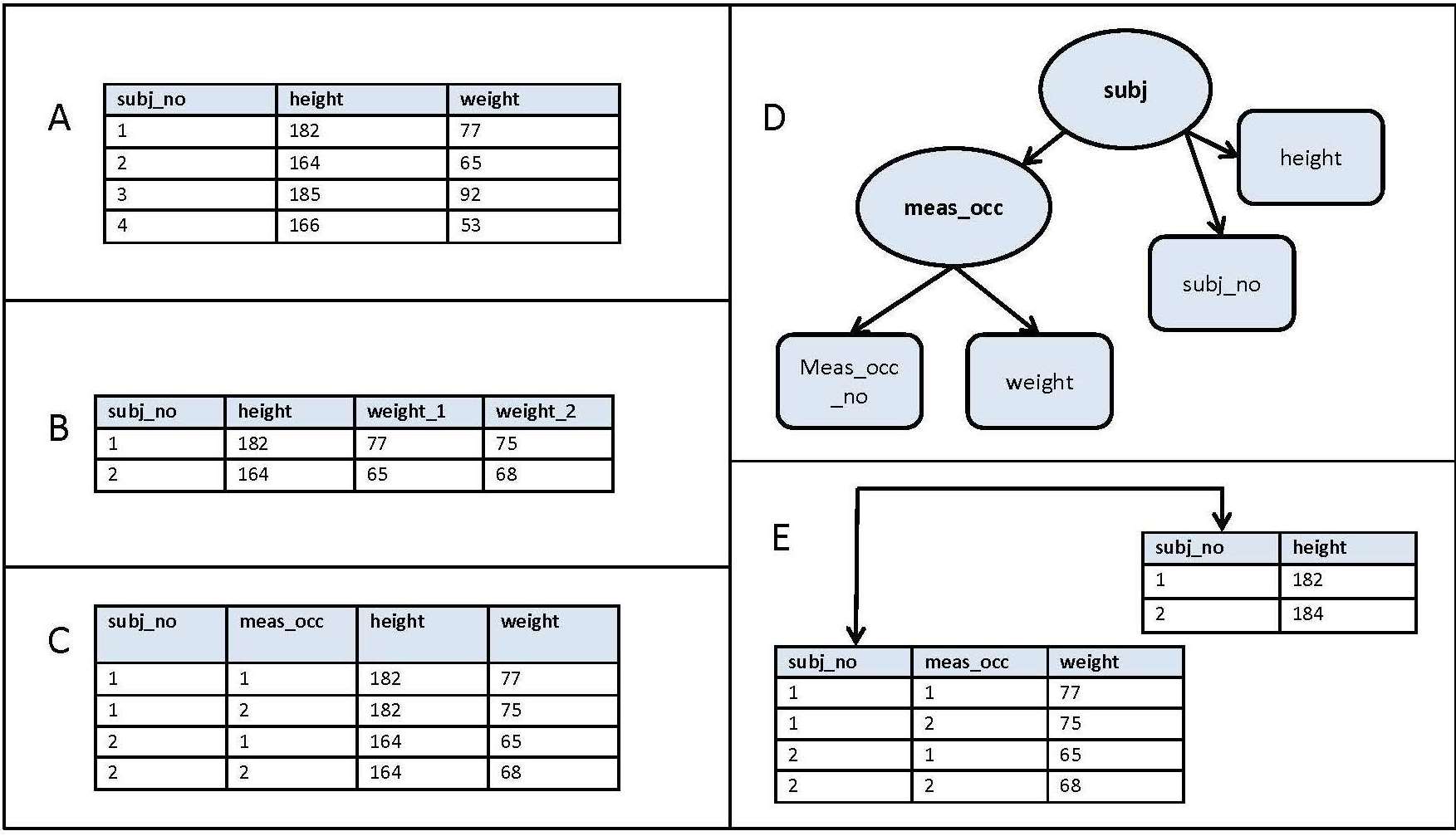
- Flat rectangular files or tabular data is a classical and still often used data structure which can be read by all statistical and spreadsheet programs.
- A common way to structure rectangular files is the wide format (table A in the image above): columns represent different variables, while lines represent different observations (e.g. subjects). However, problems in wide format arise when data is hierarchically structured, e.g. in designs with repeated measures (see table B in the image above). If the number of measurement occasions differs between observations, many cells will be left empty by design.
- One solution can be to use the long format for the data set (see table C in the image above). In long format every line depicts one observational unit (e.g. one measurement occasion for a specific person) and a variable characterizes the measurement occasion (e.g. day 1, pre-test etc.). This format permits the representation of hierarchical data in a classical rectangular file. Files in long format will contain some redundancies, because features of the higher order observation units are repeated in every line (e.g. time-invariant variables like subject’s gender or year of birth). As functions within statistical packages usually work with one of these formats only, transformations between wide-format and long-format are a frequent task and corresponding functions exist (e.g. the reshape function and the reshape2 package in R).
- Hierarchical files can be employed to avoid redundancies, that occur, when using rectangular files (see table E in the image above). XML files fulfill this requirement and allow to save data and metadata in one single file. However, despite these advantages XML-files are not commonly used in psychology and statistical software often requires tabular data as input.
- Relational data bases organize data of different hierarchical levels in separate rectangular tables while the different tables are connected through defined associations. Individual tables can be statistically analyzed or linked to form new tables. Relational databases can depict complex associations in an elegant way but they need more administration and knowledge of database languages (e.g SQL).
Organization of Research Data
As there are neither best practices nor naming conventions that explicitly refer to psychological research data, we recommend the guidance developed in the Project TIER: Teaching Integrity in Empirical Research as a starting point for folder and file organization in empirical research projects.
Furthermore, the general guidance on designing naming conventions of Boston University Libraries (n.d.) may be helpful:
- The file naming you choose should be used consistently throughout your files (always include the same information, in the same order)
Consider how, from a future point of view, your files should be organized, e.g. project_instrument_location_date_time_version.
- You should always include dates in your file names so that changes can be retraced; use format YYYY-MM-DD.
- Avoid the following symbols in your file names: “/ \ : * ? ” < > [ ] & $. They have specific meanings in some computer operating systems and thus, may result in misreadings or even deletion of the file.
- Don’t use spaces to separate terms, instead use underscores (_).
- Try to name folders in a descriptive way, so that it is clear what it contains, and keep the names short (15-20 characters max.)
- Also try to keep file names short and descriptive (<25 characters)
- If you do not use an automatic versioning software, include version numbers at the end of the file name (e.g. v01, v02,..) and change it every time the file is saved (also, refer to the knowledge base’s section on versioning). This is especially important if there are several people working together on the files, so that changes can be tracked.
- For your final version, use the word FINAL instead of a version number. This is especially useful and important if you share your files!
- File names should only contain one period before the file extension, e.g. project_name_date.doc NOT project.name.date.doc OR project_name_date..doc)
- If you already named many of your files, you can rename them quickly by using a file renaming application such as Bulk Rename Utility (Windows), ReNamer (Mac OS X) or PSRenamer (Mac OS X, Windows, Unix, Linux), and Zamzar (convert files online).
The DataWiz web application assists you in organizing your research data by offering a predefined structure and documentation scheme for your research project.
Further Resources
- SQL is a programming language that is specialized on managing data in relational database management systems.
- XML is an interoperable human- and machine-readable markup language and is widely used in research data management due to its simplicity and generic usability.
References
- Boston University Libraries (n.d.). Organizing your data. Retrieved from https://www.bu.edu/data/manage/naming-convention/